How innodb-flush-log-at-trx-commit saved the day
During a recent performance test on one of my MySQL instances, I noticed the Disk I/O Utilization graph pegged at 100%. Queries started slowing down, and it was clear the instance was hitting an I/O bottleneck.
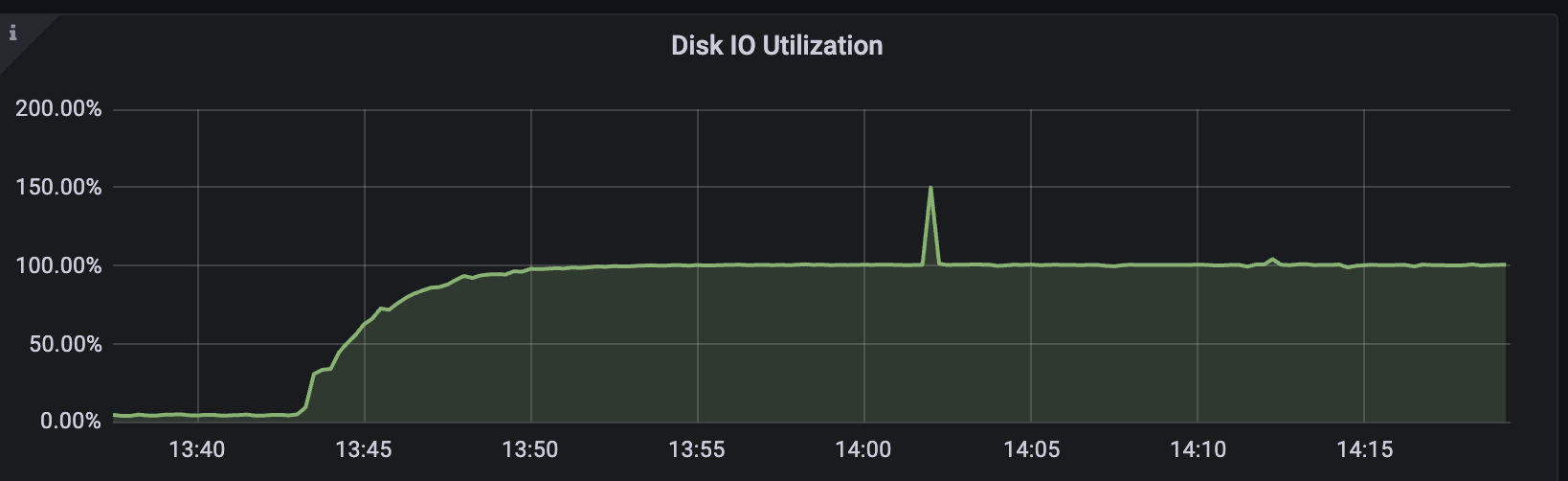
Step 1: Spotting the Symptom
Grafana first alerted me that something was off:
The utilization graph climbed steadily until it flatlined at 100%. Something inside MySQL was hammering the disk.
Step 2: OS-Level Debugging
I logged into the Ubuntu server and started with iostat:
iostat -x 1 5
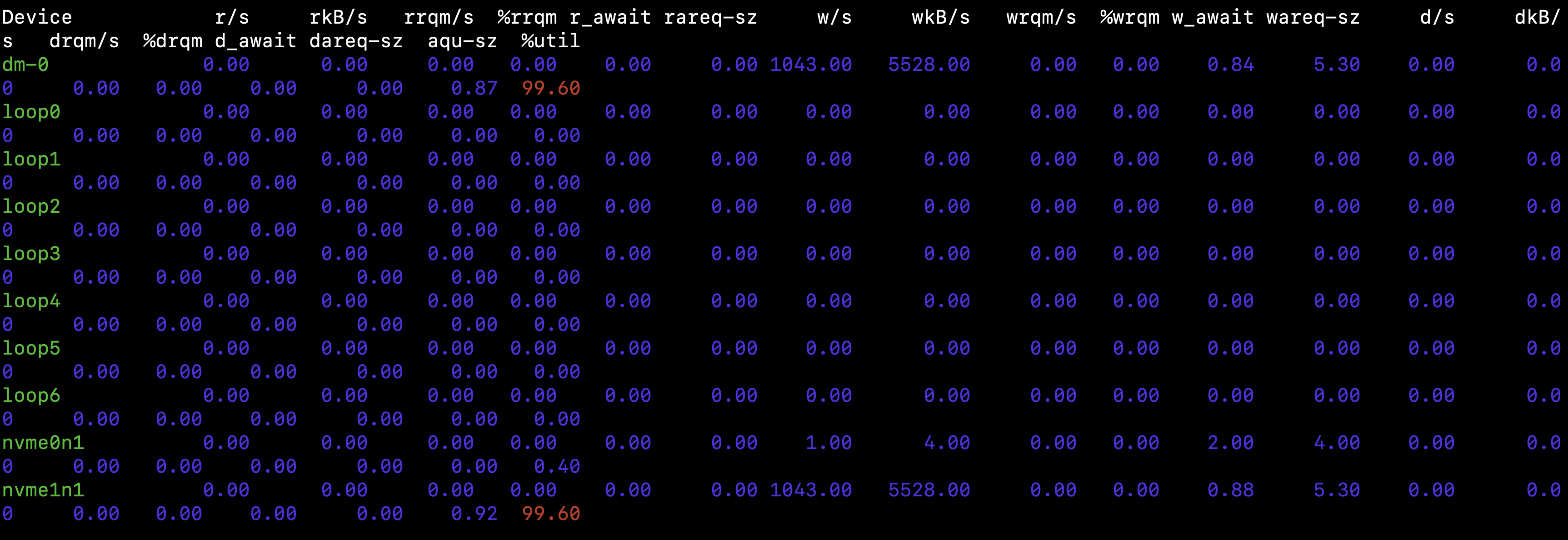
The output showed:
-
%util on nvme1n1 / dm-0 → 99-100%
-
Very high writes/sec (~1000+) with tiny block sizes (~5 KB)
-
Almost no reads happening
This pointed to frequent small write flushes saturating the disk, not big sequential reads/writes.
Step 3: Looking Inside MySQL
Next, I turned to MySQL internals. I checked the InnoDB log flush setting:
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
It was set to 1 (the default), which meant:
- InnoDB writes and flushes the redo log to disk at every single transaction commit.
- Guarantees durability (ACID compliance).
- But with lots of small transactions, this results in one fsync per commit → death by IOPS.
This perfectly explained the 5 KB writes and the saturated disk.
Step 4: The Fix
I changed the parameter to 2:
SET persist innodb_flush_log_at_trx_commit = 2;
With this setting, InnoDB still writes logs at every commit but only flushes them to disk once per second.
Result?
Disk utilization plummeted from 100% to almost idle instantly.
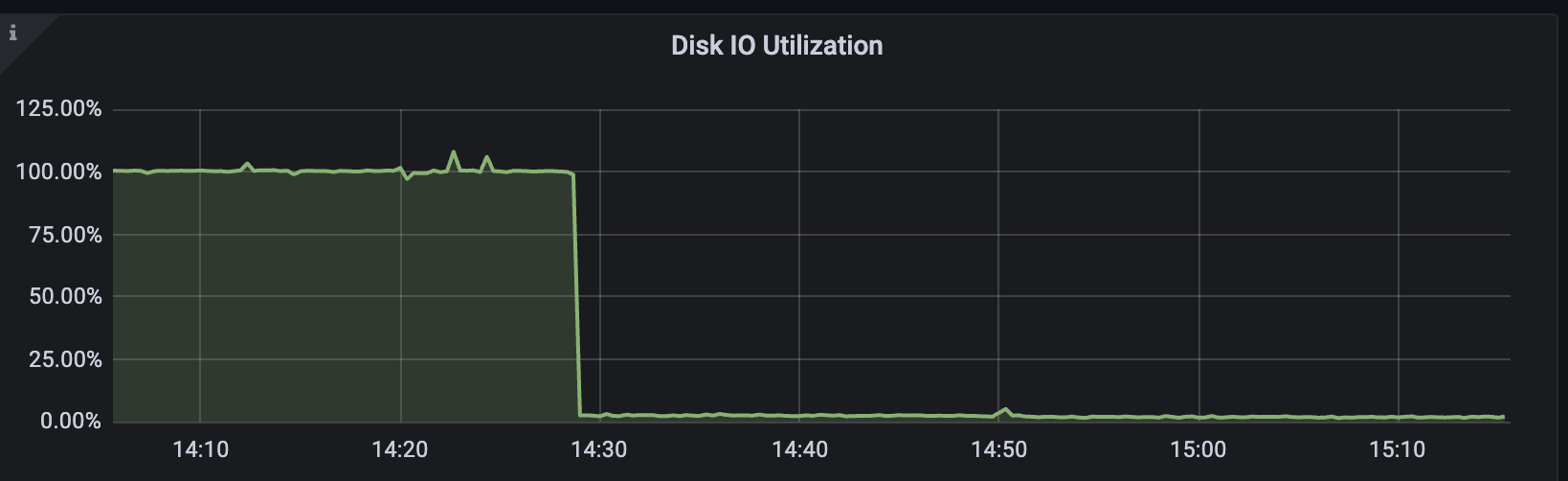
Step 5: Why This Works
Here’s the difference:
=1 → Every commit = redo log write + fsync → extremely high IOPS, guaranteed durability.
=2 → Redo log write per commit, fsync once per second → huge IOPS savings, but risk of losing up to 1 second of transactions in case of a crash.
Final Thoughts
This was a good reminder that MySQL’s default settings are tuned for safety, not performance. Knowing how InnoDB’s redo log flushing works, and when to adjust it, can save you from unnecessary I/O bottlenecks.
In my case, simply switching innodb_flush_log_at_trx_commit from 1 to 2 allowed me to bring disk utilization down and continue stress testing without hitting hardware limits.